
Dataset and metrics
for predicting local visible differences
1 MPI Informatik 2University College London 3University of Cambridge 4Università della Svizzera italiana
5Saarland University, MMCI 6West Pomeranian University of Technology, Szczecin
Abstract
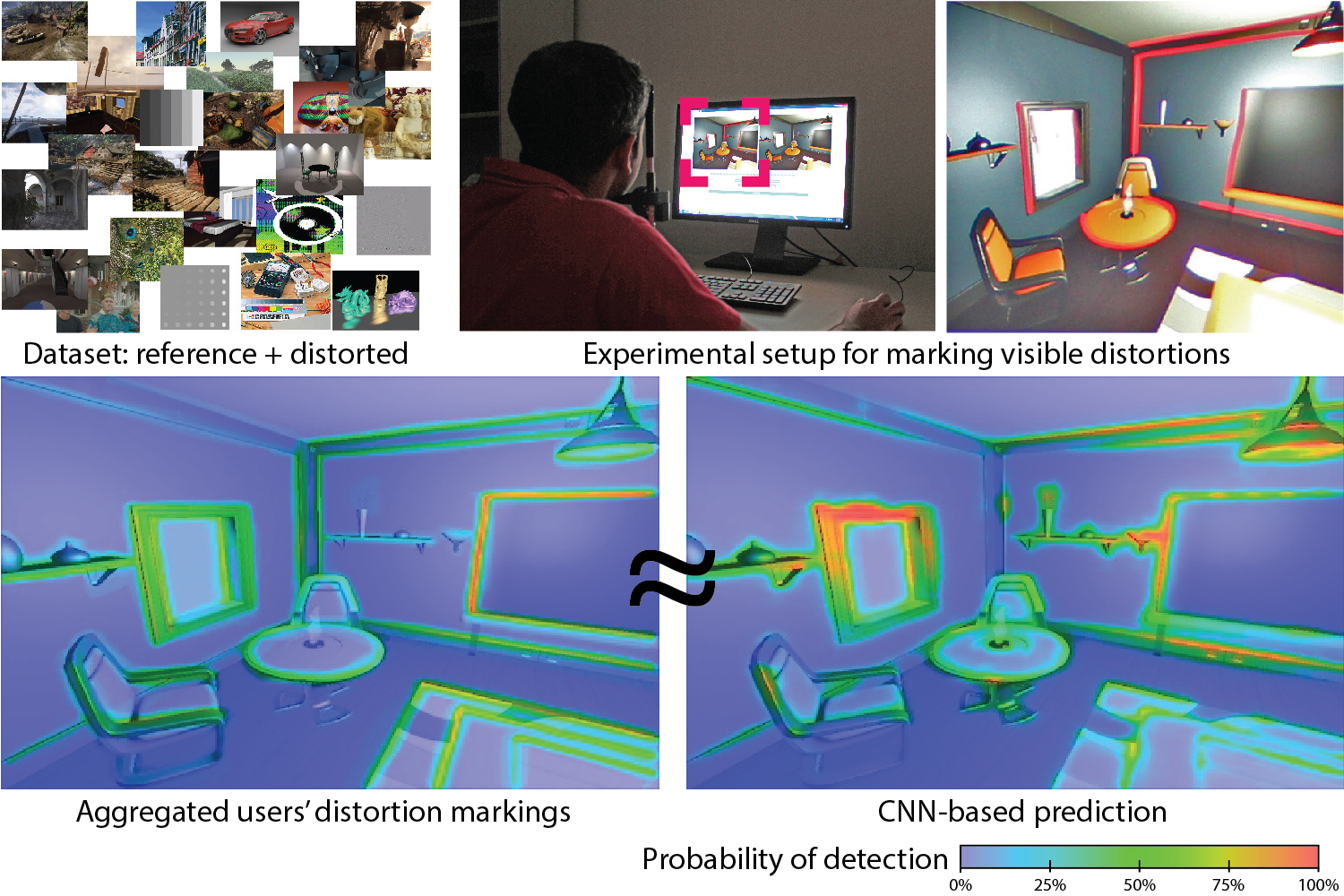
A large number of imaging and computer graphics applications require localized information on the visibility of image distortions. Existing image quality metrics are not suitable for this task as they provide a single quality value per image. Existing visibility metrics produce visual difference maps, and are specifically designed for detecting just noticeable distortions but their predictions are often inaccurate.} In this work, we argue that the key reason for this problem is the lack of large image collections with a good coverage of possible distortions that occur in different applications. To address the problem, we collect an extensive dataset of reference and distorted image pairs together with user markings indicating whether distortions are visible or not. We propose a statistical model that is designed for the meaningful interpretation of such data, which is affected by visual search and imprecision of manual marking. We use our dataset for training existing metrics and we demonstrate that their performance significantly improves. We show that our dataset with the proposed statistical model can be used to train a new CNN-based metric, which outperforms the existing solutions. We demonstrate the utility of such a metric in visually lossless JPEG compression, super-resolution and watermarking.
Materials
- Paper (PDF, 8.01 MB)
- Supplemental material low / high res (PDF, 17 / 207 MB)
- Metrics Comparison (HTML)
- Dataset (Images, 502 MB)
- CNN metric code (git repository)
- CNN metric TF model (ZIP, 404 MB)
Distortion examples
This tool allows you to compare a few examples from our dataset to the ground truth images. First, select an artifact from the list below. Then, move the white bar to switch between the reference and distorted images respectively.












Acknowledgements
The authors would like to thank Shinichi Kinuwaki for helpful discussions. The project was supported by the Fraunhofer and Max Planck cooperation program within the German pact for research and innovation (PFI). This project has also received funding from the European Union's Horizon 2020 research and innovation programme, under the Marie Skłodowska-Curie grant agreements No 642841 (DISTRO), No 765911 (RealVision) and from the European Research Council (ERC) (grant agreement nº 725253/EyeCode).